1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Technology
Mobile software developer achieves 98.8% resource savings on data
Even if you are a developer yourself, engaging subject-matter experts is always better
Data warehouse development

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Technology
Mobile software developer achieves 98.8% resource savings on data
Even if you are a developer yourself, engaging subject-matter experts is always better
Data warehouse development
Who we worked with
Client overview
A global mobile software developer

Who we worked with
Client overview
A global mobile software developer
What we did
Project overview
- Problem
Our client was grappling with a cluttered data storage system. The data extraction process became so long that the daily data couldn’t all be downloaded within that day. On top of that, database errors constantly hampered work.
The situation was getting worse every day with the new data coming into the system.
- Our solution
Our primary objectives were to streamline our client’s data storage system, fasten the data retrieval process, and substantially reduce errors during data collection.
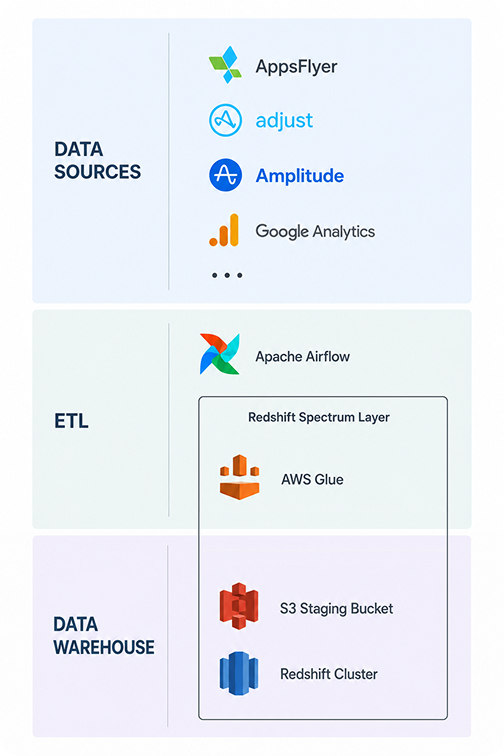
Navigating the cluttered system was a signficant challenge. After its assessment, we suggested our Client to shift it onto our codebase to efficiently sort everything.
We transitioned all ETL pipelines from conventional Python scripts to Airflow. Then we migrated the existing data warehouse by changing the Redshift cluster and moving the heaviest data sources to Redshift Spectrum.
We also implemented a specialized data pipeline for an ML model calculations using AWS Batch and Docker.
- Workflow
Our team operated fully remotely, following Agile methodology with structured sprints and bi-weekly demos to ensure continuous feedback and alignment. Transparent communication and progress tracking were maintained through Jira for task management and Slack for daily collaboration.
What we did
Project overview
- Problem
Our client was grappling with a cluttered data storage system. The data extraction process became so long that the daily data couldn’t all be downloaded within that day. On top of that, database errors constantly hampered work.
The situation was getting worse every day with the new data coming into the system.
- Our solution
Our primary objectives were to streamline our client’s data storage system, fasten the data retrieval process, and substantially reduce errors during data collection.
Navigating the cluttered system was a signficant challenge. After its assessment, we suggested our Client to shift it onto our codebase to efficiently sort everything.
We transitioned all ETL pipelines from conventional Python scripts to Airflow. Then we migrated the existing data warehouse by changing the Redshift cluster and moving the heaviest data sources to Redshift Spectrum.
We also implemented a specialized data pipeline for an ML model calculations using AWS Batch and Docker.
- Workflow
Our team operated fully remotely, following Agile methodology with structured sprints and bi-weekly demos to ensure continuous feedback and alignment. Transparent communication and progress tracking were maintained through Jira for task management and Slack for daily collaboration.
What our client achieved
99%
Resource savings
6x
Faster queries
12x
Faster raw data collection
What our client achieved
99%
Resource savings
6x
Faster queries
12x
Faster raw data collection
Repeat the success
Want the same results?
Drop us a line and we’ll show you what’s possible



About you
About your project
Related projects
1
2
3
4
5
6
7
8
9
10
11
12
13

Data modeling
Data warehouse development
1
2
3
4
5
6
7
8
9
10
11
12
13
Data architecture
1
2
3
4
5
6
7
8
9
10
11
12
13
FinTech
Development of credit scoring engine for a micro-lending marketplace
2024
6 months
7 IT experts
1
2
3
4
5
6
7
8
9
10
11
12
13
FinTech
Development of credit scoring engine for a micro-lending marketplace
2024
6 months
7 IT experts
Related projects
1
2
3
4
5
6
7
8
9
10
11
12
13
Data modeling
Data warehouse development
1
2
3
4
5
6
7
8
9
10
11
12
13
Data architecture
1
2
3
4
5
6
7
8
9
10
11
12
13
FinTech
Development of credit scoring engine for a micro-lending marketplace
2024
6 months
7 IT experts
1
2
3
4
5
6
7
8
9
10
11
12
13
FinTech
Development of credit scoring engine for a micro-lending marketplace
2024
6 months
7 IT experts