Start with understanding business requirements, data sources, analytical workloads, governance needs, and scalability goals. Then select technologies, design storage and processing layers, define governance standards, and create an implementation roadmap.
Data architecture services
Optimize, modernize or design a new data architecture for analytics, AI, and real-time decision-making

Data architecture services
Optimize, modernize or design a new data architecture for analytics, AI, and real-time decision-making

Problems
Data architecture became a bottleneck?
- Disconnected data ecosystem
Data spread across multiple warehouses, SaaS platforms, operational systems, and spreadsheets creates inconsistent reporting and fragmented business logic.
- Legacy architectures that don’t scale
Traditional warehouse-centric environments often struggle with growing data volumes, real-time requirements, and modern AI workloads.
- Slow and unreliable analytics
Poor pipeline design, duplicated transformations, and weak orchestration lead to delayed dashboards and inconsistent KPIs.
- Lack of governance and visibility
No centralized metadata, lineage, and access controls lead to compliance risks and low trust in data.
- High cloud and infrastructure costs
Inefficient storage, compute-heavy transformations, and poorly optimized ingestion patterns increase operational spending.
- Batch-only architectures
A lot of platforms don’t support streaming ingestion, real-time processing, or low-latency analytics required for modern operations.
- Inconsistent data models
Different teams define metrics and entities differently, making it difficult to establish a unified semantic layer across the business.
- AI initiatives blocked by poor foundations
Machine learning and AI programs often fail because underlying data architectures lack quality, governance, scalability, and interoperability.

Problems
Data architecture became a bottleneck?
- Disconnected data ecosystem
Data spread across multiple warehouses, SaaS platforms, operational systems, and spreadsheets creates inconsistent reporting and fragmented business logic.
- Legacy architectures that don’t scale
Traditional warehouse-centric environments often struggle with growing data volumes, real-time requirements, and modern AI workloads.
- Slow and unreliable analytics
Poor pipeline design, duplicated transformations, and weak orchestration lead to delayed dashboards and inconsistent KPIs.
- Lack of governance and visibility
No centralized metadata, lineage, and access controls lead to compliance risks and low trust in data.
- High cloud and infrastructure costs
Inefficient storage, compute-heavy transformations, and poorly optimized ingestion patterns increase operational spending.
- Batch-only architectures
A lot of platforms don’t support streaming ingestion, real-time processing, or low-latency analytics required for modern operations.
- Inconsistent data models
Different teams define metrics and entities differently, making it difficult to establish a unified semantic layer across the business.
- AI initiatives blocked by poor foundations
Machine learning and AI programs often fail because underlying data architectures lack quality, governance, scalability, and interoperability.

Our data architecture services
01.
Data architecture consulting
We’ll evaluate scalability, governance, interoperability, and platform maturity across your existing data ecosystem and suggest improvement options.
02.
Data architecture design
We’ll design modern cloud-ready data architectures for analytics, AI, governance, and real-time processing.
03.
Data architecture optimization
We’ll improve platform reliability, performance, observability, and cloud cost efficiency as data volumes grow.
04.
Data architecture modernization
We’ll modernize legacy warehouses and fragmented pipelines into scalable lakehouse and unified data platforms.
05.
Real-time data enablement
We’ll enable streaming ingestion, event-driven processing, and low-latency analytics capabilities within your architecture.


Tell us what you need
And we’ll help you achieve it
Tell us what you need
And we’ll help you achieve it
PROCESS
Data architecture delivery process
Here’s how we’ll work with you:

STEP 1
Discovery & assessment
We analyze your current data ecosystem, platforms and pipelines to identify scalability bottlenecks, governance gaps, technical debt, and modernization opportunities.
Duration: (1–2 Weeks)

STEP 2
Technology stack selection
We chose the technologies, platforms and storages that align with your scalability goals, analytical workloads, existing infrastructure, and long-term maintenance requirements.
Duration: (1–2 Weeks)

STEP 3
Design & roadmapping
We design the target-state architecture and prepare a modernization roadmap covering migration priorities, implementation phases, dependencies, and architectural standards.
Duration: (2–4 Weeks)

STEP 4
Implementation
Upon request, we help you implement the new architecture, migrate data and modernize your existing ecosystem. We can also train your staff on efficiently using the new tools.
Duration: (4–16+ Weeks)
PROCESS
Data architecture delivery process
Here’s how we’ll work with you:
STEP 1
Discovery & assessment
We analyze your current data ecosystem, platforms and pipelines to identify scalability bottlenecks, governance gaps, technical debt, and modernization opportunities.
Duration: (1–2 Weeks)
STEP 2
Technology stack selection
We chose the technologies, platforms and storages that align with your scalability goals, analytical workloads, existing infrastructure, and long-term maintenance requirements.
Duration: (1–2 Weeks)
STEP 3
Design & roadmapping
We design the target-state architecture and prepare a modernization roadmap covering migration priorities, implementation phases, dependencies, and architectural standards.
Duration: (2–4 Weeks)
STEP 4
Implementation
Upon request, we help you implement the new architecture, migrate data and modernize your existing ecosystem. We can also train your staff on efficiently using the new tools.
Duration: (4–16+ Weeks)
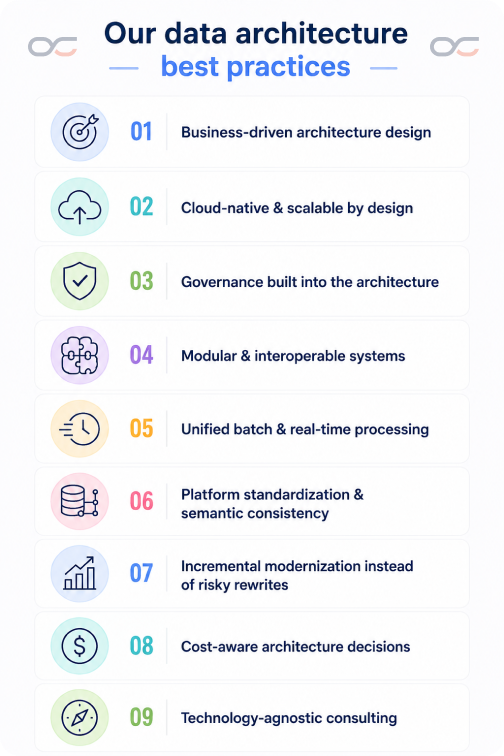
Best practices
Our data architecture best practices
- Business-driven architecture design
Architecture decisions should support business capabilities, not just technical requirements. We align platform design, data models, and integration patterns with your reporting needs, operational processes, scalability goals, and future analytical initiatives.
- Cloud-native & scalable by design
We build architectures optimized for elasticity, distributed processing, and modern cloud environments. This allows platforms to scale efficiently as data volumes, workloads, and business complexity increase.
- Governance built into the architecture
Governance should not be treated as a separate afterthought. We incorporate metadata management, lineage, access control, security, and data quality practices directly into architectural design from the beginning.
- Modular & interoperable systems
We favor loosely coupled, modular architectures that simplify integration, reduce vendor lock-in, and allow individual platform components to evolve independently over time.
- Unified batch & real-time processing
The demand today grows for both historical analytics and low-latency operational insights. We design architectures capable of supporting batch, streaming, and hybrid processing models within a cohesive ecosystem.
- Platform standardization & semantic consistency
We help you establish shared architectural standards, reusable data models, and consistent business definitions that improve interoperability and reduce duplicated logic across teams and platforms.
- Incremental modernization instead of risky rewrites
Large-scale platform rewrites often introduce unnecessary operational and business risk. We prioritize phased modernization approaches that allow you to improve architecture progressively while maintaining continuity for existing workloads and users.
- Cost-aware architecture decisions
Scalable architectures should also remain operationally efficient. We consider storage, compute, orchestration, and data movement costs when designing platforms to help optimize long-term cloud and infrastructure spending.
- Technology-agnostic consulting
We design architectures based on technical fit, scalability requirements, and business constraints rather than forcing organizations into a specific vendor ecosystem or tooling stack.
benefits
Our data architecture best practices
- Business-driven architecture design
Architecture decisions should support business capabilities, not just technical requirements. We align platform design, data models, and integration patterns with your reporting needs, operational processes, scalability goals, and future analytical initiatives.
- Cloud-native & scalable by design
We build architectures optimized for elasticity, distributed processing, and modern cloud environments. This allows platforms to scale efficiently as data volumes, workloads, and business complexity increase.
- Governance built into the architecture
Governance should not be treated as a separate afterthought. We incorporate metadata management, lineage, access control, security, and data quality practices directly into architectural design from the beginning.
- Modular & interoperable systems
We favor loosely coupled, modular architectures that simplify integration, reduce vendor lock-in, and allow individual platform components to evolve independently over time.
- Unified batch & real-time processing
The demand today grows for both historical analytics and low-latency operational insights. We design architectures capable of supporting batch, streaming, and hybrid processing models within a cohesive ecosystem.
- Platform standardization & semantic consistency
We help you establish shared architectural standards, reusable data models, and consistent business definitions that improve interoperability and reduce duplicated logic across teams and platforms.
- Incremental modernization instead of risky rewrites
Large-scale platform rewrites often introduce unnecessary operational and business risk. We prioritize phased modernization approaches that allow you to improve architecture progressively while maintaining continuity for existing workloads and users.
- Cost-aware architecture decisions
Scalable architectures should also remain operationally efficient. We consider storage, compute, orchestration, and data movement costs when designing platforms to help optimize long-term cloud and infrastructure spending.
- Technology-agnostic consulting
We design architectures based on technical fit, scalability requirements, and business constraints rather than forcing organizations into a specific vendor ecosystem or tooling stack.
Technologies
Our data architecture technologies:
/
BigQuery
Snowflake
Databricks
Airflow
/
/
Kafka
Synapse
dbt
AWS
GCP
/
/
Apache Spark
/
WHY US
Why clients choose us

100 years of combined expertise
We know how to create solutions that deliver results.
Top 3% talent
We rigorously vet candidates for skill, experience, and communication.
Up-to-date tech stack
We keep track of the latest industry advancements, attend workshops and share knowledge with experts.
Transparent communication
We are all English-speaking professionals, aligned with your timezone.
Proven track record
We are trusted by clients in finance, healthcare, logistics and e-commerce.
WHY US
Why clients choose us
100 years of combined expertise
We know how to create solutions that deliver results.
Top 3% talent
We rigorously vet candidates for skill, experience, and communication.
Up-to-date tech stack
We keep track of the latest industry advancements, attend workshops and share knowledge with experts.
Transparent communication
We are all English-speaking professionals, aligned with your timezone.
Proven track record
We are trusted by clients in finance, healthcare, logistics and e-commerce.
CONTACT US
Architect your data
Get a unified, cloud-ready architecture designed for enterprise analytics, governance, and AI initiatives.

Mikhail Hishkialiuk
Head of Technology Partnerships

Dmitri Kuchinski
Chief Operating Officer

Ula Dzenisevich
Chief Business Development Officer
About you
About your project
FAQS
Frequently asked questions
How to build a data architecture?
When should we modernize our data architecture?
Consider modernization when existing platforms can no longer support growing data volumes, real-time requirements, governance standards, or new analytical initiatives. Common signs include fragmented reporting, slow data pipelines, scalability bottlenecks, rising infrastructure costs, inconsistent business metrics, and difficulties supporting AI or advanced analytics workloads.
Can you modernize existing data platforms without rebuilding everything?
Yes. In most cases, a full platform rebuild is unnecessary and introduces significant operational risk. We usually recommend incremental modernization approaches that improve specific architectural layers over time — such as storage, processing, governance, or orchestration — while keeping critical business operations running throughout the transition.
How much do data architecture services cost?
The cost depends on the scope, complexity, and maturity of the existing data ecosystem. Smaller architecture assessments and advisory engagements may take a few weeks, while enterprise modernization initiatives involving cloud migration, governance implementation, or real-time enablement can become long-term programs. We typically define project scope and delivery approach after an initial discovery phase.
Which cloud platforms and technologies do you support?
We work across modern cloud and data ecosystems, including AWS, Microsoft Azure, Google Cloud Platform, Snowflake, Databricks, BigQuery, Microsoft Fabric, Kafka, Spark, dbt, Airflow, and other modern analytics and data processing technologies. Our approach remains technology-agnostic and focused on selecting platforms that best fit business and architectural requirements.
Can you help prepare our architecture for AI and machine learning initiatives?
Yes. Modern AI initiatives require scalable, well-governed, and high-quality data foundations. We help organizations design architectures that support machine learning workflows, real-time data processing, feature engineering, semantic consistency, governance, and scalable analytical workloads necessary for AI and advanced analytics adoption.
What is a data warehouse architecture?
A data warehouse architecture is a centralized approach for storing curated and structured data optimized for reporting, business intelligence, and historical analysis. It typically includes data ingestion, transformation, storage, semantic modeling, and consumption layers.
What is a data lake architecture?
A data lake architecture stores structured, semi-structured, and unstructured data in its raw form within scalable object storage. It enables centralization of large data volumes while supporting analytics, machine learning, and data science workloads without requiring predefined schemas.
What is a data lakehouse architecture?
A data lakehouse architecture combines the scalability and flexibility of data lakes with the governance, reliability, and performance traditionally associated with data warehouses. It enables analytics, reporting, and AI workloads to operate on a unified data platform.
When should we use a data lakehouse architecture?
Data lakehouse architecture is often a good choice when you need to support analytics, machine learning, and large-scale data processing on a single platform. It is particularly valuable when both structured and unstructured data must be managed while maintaining governance and performance.
What is a Data Mesh architecture?
Data Mesh is a decentralized approach that treats data as a product and assigns ownership to individual business domains. Instead of relying on a centralized data team, domain teams manage and publish their own data products while following shared governance standards.
What is a Data Fabric architecture?
Data Fabric is a metadata-driven approach that connects and manages data across distributed systems. It helps improve data accessibility, governance, integration, and visibility without requiring all data to be physically centralized.
What is a semantic layer in a data architecture?
A semantic layer provides a consistent business view of data by defining shared metrics, dimensions, and business rules. It helps ensure that reports, dashboards, and analytical applications use the same definitions across the organization.
What is a big data architecture?
Big data architecture is designed to process, store, and analyze large volumes of high-velocity and diverse data. It typically combines distributed storage, scalable processing engines, streaming technologies, and analytics platforms to support large-scale analytical workloads.
What is an enterprise data architecture?
An enterprise data architecture defines how data is managed, integrated, governed, and consumed across an enterprise. It provides a framework for aligning data platforms, business processes, governance policies, and analytical capabilities with enterprise objectives.
What is a data flow architecture?
A data flow architecture describes the conceptual path of how data travels through systems, applications, and processing layers. It defines the movement, transformation, storage, and consumption of data across the entire data ecosystem.
What is a data pipeline architecture?
A data pipeline architecture refers to the specific technical implementation of how data moves from source systems to storage and consumption layers. It includes ingestion mechanisms, transformation processes, orchestration, monitoring, and delivery patterns that ensure reliable and scalable data flows.
FAQS
Frequently asked questions
How to build a data architecture?
Start with understanding business requirements, data sources, analytical workloads, governance needs, and scalability goals. Then select technologies, design storage and processing layers, define governance standards, and create an implementation roadmap.
When should we modernize our data architecture?
Consider modernization when existing platforms can no longer support growing data volumes, real-time requirements, governance standards, or new analytical initiatives. Common signs include fragmented reporting, slow data pipelines, scalability bottlenecks, rising infrastructure costs, inconsistent business metrics, and difficulties supporting AI or advanced analytics workloads.
Can you modernize existing data platforms without rebuilding everything?
Yes. In most cases, a full platform rebuild is unnecessary and introduces significant operational risk. We usually recommend incremental modernization approaches that improve specific architectural layers over time — such as storage, processing, governance, or orchestration — while keeping critical business operations running throughout the transition.
How much do data architecture services cost?
The cost depends on the scope, complexity, and maturity of the existing data ecosystem. Smaller architecture assessments and advisory engagements may take a few weeks, while enterprise modernization initiatives involving cloud migration, governance implementation, or real-time enablement can become long-term programs. We typically define project scope and delivery approach after an initial discovery phase.
Which cloud platforms and technologies do you support?
We work across modern cloud and data ecosystems, including AWS, Microsoft Azure, Google Cloud Platform, Snowflake, Databricks, BigQuery, Microsoft Fabric, Kafka, Spark, dbt, Airflow, and other modern analytics and data processing technologies. Our approach remains technology-agnostic and focused on selecting platforms that best fit business and architectural requirements.
Do you provide implementation support after the architecture design phase?
Yes. In addition to architecture strategy and design, we can support implementation, migration, modernization, governance setup, and optimization activities. Depending on the engagement model, we work alongside internal teams or provide end-to-end delivery support to help ensure successful adoption of the target architecture.
What is a data warehouse architecture?
A data warehouse architecture is a centralized approach for storing curated and structured data optimized for reporting, business intelligence, and historical analysis. It typically includes data ingestion, transformation, storage, semantic modeling, and consumption layers.
What is a data lake architecture?
A data lake architecture stores structured, semi-structured, and unstructured data in its raw form within scalable object storage. It enables centralization of large data volumes while supporting analytics, machine learning, and data science workloads without requiring predefined schemas.
What is a data lakehouse architecture?
A data lakehouse architecture combines the scalability and flexibility of data lakes with the governance, reliability, and performance traditionally associated with data warehouses. It enables analytics, reporting, and AI workloads to operate on a unified data platform.
When should we use a data lakehouse architecture?
Data lakehouse architecture is often a good choice when you need to support analytics, machine learning, and large-scale data processing on a single platform. It is particularly valuable when both structured and unstructured data must be managed while maintaining governance and performance.
What is a Data Mesh architecture?
Data Mesh is a decentralized approach that treats data as a product and assigns ownership to individual business domains. Instead of relying on a centralized data team, domain teams manage and publish their own data products while following shared governance standards.
What is a Data Fabric architecture?
Data Fabric is a metadata-driven approach that connects and manages data across distributed systems. It helps improve data accessibility, governance, integration, and visibility without requiring all data to be physically centralized.
What is a semantic layer in a data architecture?
A semantic layer provides a consistent business view of data by defining shared metrics, dimensions, and business rules. It helps ensure that reports, dashboards, and analytical applications use the same definitions across the organization.
What is a big data architecture?
Big data architecture is designed to process, store, and analyze large volumes of high-velocity and diverse data. It typically combines distributed storage, scalable processing engines, streaming technologies, and analytics platforms to support large-scale analytical workloads.
What is an enterprise data architecture?
An enterprise data architecture defines how data is managed, integrated, governed, and consumed across an enterprise. It provides a framework for aligning data platforms, business processes, governance policies, and analytical capabilities with enterprise objectives.
What is a data flow architecture?
A data flow architecture describes the conceptual path of how data travels through systems, applications, and processing layers. It defines the movement, transformation, storage, and consumption of data across the entire data ecosystem.
What is a data pipeline architecture?
A data pipeline architecture refers to the specific technical implementation of how data moves from source systems to storage and consumption layers. It includes ingestion mechanisms, transformation processes, orchestration, monitoring, and delivery patterns that ensure reliable and scalable data flows.